
AI is ready for industrial operations, but are industrial operations ready for AI?
Two hot things are happening in industrial AI adoption: contextualizing AI models and intelligence at the edge. While contextualizing got a recent boost via Retrieval-augmented generation (“RAG”) for large language models (“LLM”), progress in making efficient embedded edge devices has been brewing slowly in the hardware world for quite some time.
Now, we are at the point where both innovations intersect – the compute power of embedded platforms have expanded to have GPUs with dozens of tensor cores and more than 16 GB of memory to load large models. At the same time, LLMs are optimized and tuned to work on less powerful hardware with RAGs and embedding for domain-specific applications. It’s also important to note that many consumer devices are very AI-capable, and many of them, like the iPad, are actively used in the field.
When we hear about AI adoption, it’s mainly in the context of picking the suitable model, connecting it to the correct data, and hosting it on the right platform for optimal performance. However, scaling AI adoption within large industrial settings creates a lot of security risks. Can AI accidentally leak my data? Can AI be manipulated to carry on critical actions with escalated privileges? Can you let AI make all autonomous decisions, or do you need humans in the loop?
I think there are enough stories to say yes confidently. Last June, researchers were able to access personally identifiable information from Nvidia’s AI software. In August, another vulnerability exploited ChatGPT to expose similar private data. Beyond leaking data, large language models can inject false data or even execute code remotely.
We will most likely hear more reports as AI adoption grows in the industrial world. So, how do we address these risks and prepare for the future where AI is augmenting many industrial processes?
Let’s start with the “Human in the Loop” problem.
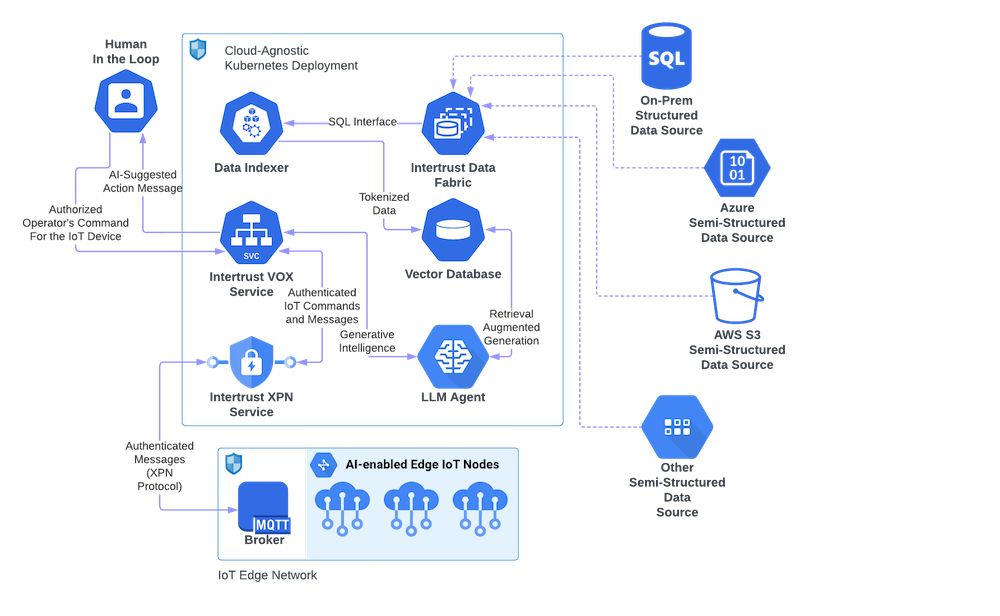
To facilitate artificial intelligence at the “edge” or make a production facility actionable, we must let AI make decisions or bubble up suggestions for human intelligence approval and execution. Many industrial processes are regulated and require responsible party sign-off. We anticipate that as regulation of AI tools will increase, so will the “Human in the Loop” problem become a more pressing security concern and a compliance requirement. Now, to protect communication between AI, humans, and critical software or equipment, we need the next level of protection, one that not only operates on the transport level (like TLS/SSL) but also operates on the application level, where you can encrypt and sign individual messages/commands to confirm the authenticity of each step in the decision making and leaves a corresponding trace in an audit system.
Let’s look into infrastructure where learned models are trained, augmented, and hosted. But there are even more stories about training data being publicly accessible on the internet, including highly sensitive data. How can one protect such sensitive data throughout the whole AI lifecycle?
Level One: Isolate the training process with virtualization; structured data should be governed with row and column-level access control, training should be done in virtualized environments like Kubernetes, and unstructured data should be mounted into the virtualized environment during model training launch, PII and other sensitive elements within the training dataset should be masked or hashed.
Level Two: RAGs, embeddings, and Vector Databases. Segment vector data into different stores with access control so each model deployment can access individual vector stores with unique credentials.
There are a wide range of AI solutions today, but most are consumer-grade and must be protected enough to be deployed in industrial settings. To take advantage of the new AI tech, enterprises need a team of in-house experts, external consultants, or software to help them safely manage such integrations. Considering the trajectory of LLMs and the lack of professionals in that domain, it makes it expensive to hire in-house AI experts or external consultants; having a self-service infrastructure for data governance, model deployment, and security would allow businesses to move forward with market trends controlling the risks and the budgets.
While industry is in the early stages of this process, we believe it is never too early to ensure your systems are AI-ready. Our Virtual Operations Center (VOX) is built on the principles outlined above. VOX integrates data from many sources through a governance layer that prevents data leakage. By employing advanced security measures like Explicit Private Networking (XPN) , VOX not only safeguards against data leakage but also ensures that each step in the AI decision-making process is authorized and traceable. Our secure communication SDK – XPN provides a ‘Human in the Loop’ solution and ensures regulated industrial processes. Together, VOX and XPN provide a secure, centralized platform across the AI lifecycle.
As we navigate the evolving landscape of AI in industrial operations, the importance of deploying AI securely is greater than ever. If you are considering making your systems AI-ready or have concerns about integrating AI into your existing infrastructure, please feel free to contact us.

About Ilya Khamushkin
As Manager of Customer Solutions Engineering, Ilya is at the forefront of Intertrust's customer success. He has two decades of engineering experience and specialized in enterprise software integration and solution design for the last six years, with a focus on AI/ML, data pipelines, and business intelligence.

